Macintosh
MacBook Airの妥協点
a point of compromise
パソコンを使用中に「新型ですか?」と聞かれることはあっても、閉じたまま机の上においただけで注目をあつめたのは初めてだった。
pynrynを搭載したMacBook/Macbook Proと比較すると、既に旧式かもしれない。しかしデザインを含めたパッケージ全体を評価するためには、新しい物差しが必要だ。
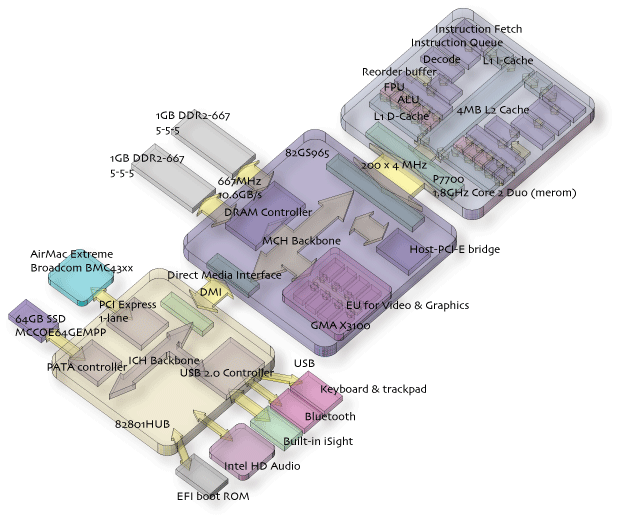
パッケージとしてみた場合、Ethernetの削除は小型化という部分よりも、Airの使い方自体を提案するための方便だろう。Intelの標準的チップセットを使っている以上、回路が省かれているわけではなく、物理層が省略されているだけだ。
FireWireに関しては、PCI-Eブリッジと物理層を用意する必要があり、削除は小型化、省電力化などに寄与している。インターフェースが足りないだけでブロック図は、meromを搭載した一つ前のMacBookとほぼ同じである。
グラフィックサブシステムに注目したとき、GMA X3100をnVideaなどの外付けGPUと比較するべきではないだろう。もちろんチップセット内蔵GPUとはいっても、ユーザーインターフェースを改善するCore Imageなどハードウェアアクセラレーションに関しては、十分な性能をもち、Video再生支援回路は、CPUの負荷を下げることができる。
SSDが旧式で早いとは言えないATA66で接続されているが、これは供給されているSSDのインターフェース側の問題である。全体として目新しさはなく、オーソドックスな作りだ。
これまでAppleのハードウェアはPowerPCという特殊性からCPUとNorth bridgeまではCPUベンダーから供給を受け、South biridgeはカスタムチップが使われることが多かった。そういう意味から主要チップがIntel一社から供給されているので、より細やかな電力コントロールができるようになったともとれる。
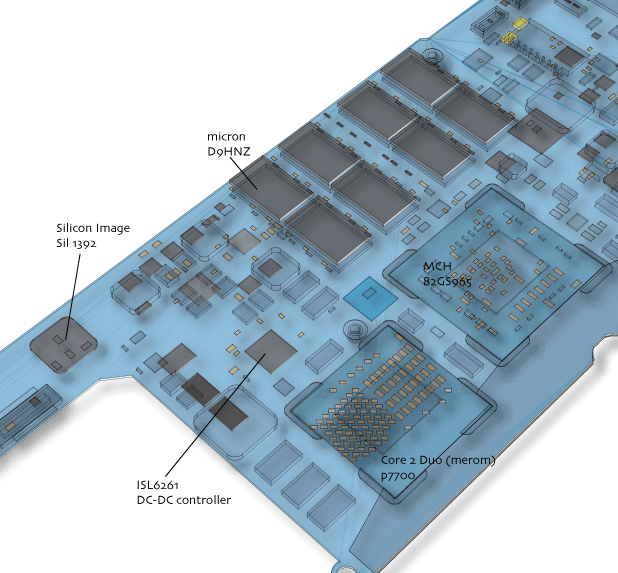
logic boardはPowerBook G4 17inchの時からずっと、主要部品面が裏側になるように組み込まれてきた。そのためキーボードの後ろ側は、電源制御チップのISL6261 DC-DC Controllerなどが並んでいる。
例外として1GB分のDDR2-667メモリ、micron社の D9HNZが8個搭載されている。アクセスタイミングは5-5-5-12で、ノースブリッジ(MCH)がDDR2-667で対応する唯一のタイミングである5-5-5に合致する。Silicon Image SiI1392は HDMI Transmitter (HDMI 1.2)で、HDMIのコンテンツ保護回路としてMCHに外付けされている。Intelは次の世代のMCHにこの機能を内蔵するとアナウンスしている。
さて基板よりも大きなフットプリントを持つのがリチウムポリマー電池で、その容量は37Whだ。MacBook Pro 15が60Wh、MacBook Pro 17が68Wh、ほぼ同じ構成のMacBookでも61Whであることから考えると、省電力に苦心したことが伺える。

本体裏側、ボトムケース表面を放射温度計で測定すると、CPU付近の温度は体温とそれほどかわらない36度から38度程度であった。逆にそれほど温度が高くないと思われたSSD付近は41度に達している。
このとき、排気口部の温度は46度に達しており、上手に内部の熱を排出していた。微妙なカーブを描いているため、温度の高い部分が直接肌に触れることはあまりなく、快適に利用できる。
Intel Macとなり、MacBookに使用されているCPUは3世代の変遷を遂げた。最初に65nmを導入したCore Duo(Yonah),おなじ65nmながらSSE演算部分の強化やIntel 64を実現するなど実行ユニットに大幅な手を加えたCore 2 Duo (Merom)、さらに45nmへとプロセスルールを微細化したCore 2 Duo (Penryn)だ。
いずれもCoreという名称がついているため紛らわしいが、CoreマイクロアーキテクチャはMeromからで、Yonahはこれに含まれない。Yonahは省電力、高効率なCPUとしてMacintoshがIntelへ移行するきっかけとなったCPUで、比較的パイプラインが短く、モバイル用Pentium Mを祖としている。このPentium Mはμopsフュージョンと、強力な分岐予測を持っていた。
移行前のPowerPC G5にもこのμopsフュージョンに似た構造がみられます。 G5も命令を単純なものへ分解し、長いパイプラインには200個も命令が保持されていた。さらに命令を5個一組のグループに再合成し、グループ単位で例外処理を行うことで、回路を単純化した。マイクロOpsフユージョンも2つの命令を効率よく連結してはいるが、これは小さなパイプラインバブルをつぶし、高速化する性格のもので、電力効率が改善する。G5のグループ化はどちらかというと、パイプラインの小さなバブルの発生を気にかけるより、回路の単純化と高速化をねらったものだ。
Pentium Mは分岐予測も優れていた。同時代のPowerPC G5はPentium 4同様、パイプラインが長く分岐予測ミスの代償は大きいので、分岐予測回路に多くの半導体が裂かれていた。分岐ごとの状態保持エントリー数はPentium 4の4倍の16Kエントリーだ。ただし「分岐したか」「分岐しないか」の保持しかしない1bitのローカル分岐履歴テーブルで、一般的なシュミュレーションでは4Kエントリーを超える分岐履歴テーブルの効果はそれほど認められず、それよりも状態保持を2bitにしたbi-modalの精度がよいとされている。
PowerPC G4も2Kエントリーのbi-modalだ。2bitあれば「2回連続でミスすれば、3回目からはミスをしない」という保持ができる。なぜ1bitなのかは、G5の分岐予測が二層構造になっていて、いずれも16K単位であったことに関係するかもしれない。1回のフェッチで8個の命令をパイプラインに取り込むが、過去11回分のフェッチが分岐せずに読み込まれたのか、それとも分岐が発生したのかを順次保存しておいて、分岐命令の場所と履歴からハッシュ値を求め、16Kエントリー分とっておく。このグローバル分岐テーブルは短めのループを見つけ出して的確に分岐するための仕組みといえる。
前述の1bitのローカル分岐履歴とグローバル分岐履歴の二つのうちどちらが役に立ったかを記録する16Kエントリーをがある。2段重ねになった複合型分岐予測は、分岐ミスを極力なくしてパイプラインストールを防いでいた。
分岐予測にともなう投機的実行の失敗は無駄な発熱、バッテリー消費を意味するので、効率という意味から重要だ。Pentium Mはさらに上をいっていた。ループを事前に探しておいて、専用のループカウンターで予想するループ検出器はG5のグローバル分岐予測よりも大域のループを予想できるだろう。効率の良い4Kの2bit(Bi-modal branch prediction)とループ検出器の組み合わせに、さらにグローバル分岐予測を組み合わせた構造になっていた。グローバル分岐予測にはアドレスごとに使用するかしないかのテーブルと履歴テーブルを組み合わせたもので、動的に配置される命令に対して強化されていた。
G5のグローバル分岐予測がアドレスと履歴の合成(ハッシュ)で記録していたものと比較すると、コンパイラとの相性が良いだろう。
高クロックよりも処理効率の高さを狙った短めのパイプラインを持つPentium Mを元に、二つのコアで共有する2MのL2キャッシュを搭載し、65nmという当時もっとも進んだプロセスルールで製造されたのがYonahだった。このCPUは初代Intel Macに搭載されたことは記憶に新しい。
その後、Coreマイクロアーキテクチャとして64bitをサポートしたMeromを搭載したMacBook Proがデザインをかえずに発表された。Coreマイクロアーキテクチャの特徴はIntelの言葉を借りると次の5つで説明される。
ワイド・ダイナミック・エグゼキューション
14段のパイプラインで、1クロックで最大4命令を同時処理できる。マイクロOpsフユージョンで一部命令をまとめて効率化する。コンパイラに頼らずとも既存のコードを高速化するとされている。
アドバンスド・スマート・キャッシュ
2次キャッシュを2つのコアで共有し、動的に配分できるようにしたもの。これには一つのダイに8個搭載されるプリフェッチエンジンが密接に関連している。キャッシュが共有だからといって、単純に二つのコアのキャッシュの相同性が保たれる訳ではない。
PowerPC 970MPはDual Coreだが、単純にL2キャッシュが分割され、I/O部分だけが共有化されていました。したがって、キャッシュの相同性を保つには、フロントサイドバスを経由し、ノースブリッジ経由で往復しつつ、L1キャッシュの相同性を保っていた。
それに対して、MoremはL2キャッシュを介してL1の相同性を保持するためのプリフェッチエンジンがそれぞれのCoreに用意されており、フロントサイドバスを占有すること無く行われる。
スマート・メモリー・アクセス
低速なメモリへのアクセスによるレイテンシを隠すために、時間のかかる読み込み命令を並べ替えて高速化するとされている。独立した読み込みを見つけ出して、先に発行するというのだ。
さらに、メモリ読み込み先をハードウェアが予測して先にキャッシュへ充填する仕組みとして、IP-Based Prefetcher to Level 1 Data Cashが注目される。ロード命令の配列場所に対応したキャッシュ格納位置と読み込みアドレス、さらにアドレス間隔の履歴を保存し、ロード後に速やかに次ぎに読み込まれそうなメモリを先読みしておくという仕組みだ。
このIP-Based Prefetcher二つと、命令用のプリフェッチ、L1キャッシュの相同性を保つプリフェッチの計4つが、それぞれのコアに装備されている。このようにプリフェッチエンジンが複雑で多く、いわゆる「投機的プリフェッチ」を行うと、フロントサイドバスが飽和することも考えられる。そこで、本来のプログラムからのロード命令を優先し、投機的プリフェッチによる副作用を防ぐために設定を調整することもできる。用途別にCPUの性格を決められるようになっているのだ。
インテリジェント・パワー機能
コアごとの動作ステートを変更可能にして消費電力を低減できる。
アドバンスド・デジタル・メディア・ブースト
Yonahでは128bit SSE命令を2分割して処理していたが、1クロックで処理できるように拡張されてた。(PowerPCはG4時代からSIMD演算は独立して1クロック処理)
こうしてみると、PowerPC G5の独立した非常に高速なフロントサイドバスにみられるボトルネックを嫌ったスマートなアーキテクチャとは異なり、Intel風の力でねじ伏せるような、複雑なアーキテクチャであることがわかる。
さて、MacBook Airの発表後、最新のMacBook ProにはPenynが採用された。L2キャッシュ容量が増加していてさらにレイテンシが隠され高速なCPUになったことがスペック表でみるとすぐにわかる。そこに現れないアーキテクチャ上の大きな違いは、Deep Power Down Technologyと最新の45nmプロセスルール、そしてそれを実現したメタルゲートとHigh-K素材だ。
これまでCPUの高性能化は微細化にともない、より多くの半導体を集積できるようになったことと、一つ一つの半導体の大きさが小さくなって、より高速に、より小さな電力でドライブできるようになったことで成り立ってきた。大量の半導体は、前述の複雑なアーキテクチャを実現し、大量のL2キャッシュをCPUコアの近くに実現して、CPUからみると低速なメインメモリのレイテンシを隠した。
しかし微細化による性能向上に黄色信号がともったのは、90nmを超えたころからだ。ちょうどPowerMac G5に使われたPowerPC 970も微細化だけではなく、SOI、銅配線、歪みSiなど採用したPowerPC 970FXになって2.5MHzの水冷モデルを実現している。Intelは65nmへさらに駒をすすめたが、あまりにも小さくなったトランジスタのゲート絶縁膜が薄くなりすぎたため、リーク電流が制御できず消費電力をへらすことが出来なくなってきた。
これまでもLow-K素材をつかった層間絶縁膜などで配線間のクロストークを減らすなど工夫はされていたが、Intelは45nmプロセスでゲート絶縁膜の素材自体を40年間使われてきた二酸化ケイ素から新たにHigh-k素材にかえることで、リーク電流を劇的に減らすことに成功した。